Fine-Tune Model
Introduction #
The snapshot created previously is now the basis for fine-tuning your model, enhancing its classification abilities with the chosen dataset. This stage allows you to refine the model’s performance and prepare it for practical application.
Part 4: Fine-Tune From a Snapshot #
Set Up Model Fine-Tuning Job #
- Go to the Models tab in your project.
- Select Fine-tune Model.

- In New model name, provide a unique model name.
- In Snapshot, select your saved snapshot. (Note: This field is an optional field.)
- Select Next.
Choose Model and Training Parameters #
- Select a Base model and a Resource Pool.
- Choose the Number of GPUs.
- Toggle Advanced Mode to access and adjust:
- Learning Rate—Controls the impact of each training step.
- Context Window—Sets the max token count for text chunks during training.
- Batch sizes (per GPU) for Training and Validation.
- Training strategy settings like Epochs, Log Cadence, and Save Cadence.
- Enable settings like FP16 for efficiency, Deep Speed for resource management, and Gradient Checkpointing if memory is limited.
- Click Next.
Pick Dataset and Splits #
- The dataset linked in your snapshot should pre-fill. Verify and adjust if necessary.
- Review and link the dataset if not already done.
- Click Next.
Review Your Prompt and Launch #
- Review the pre-loaded prompt and make any edits if needed.
- Select Launch Fine-tuning to start the fine-tuning process.
Monitor Fine-Tuning Training Job #
- To monitor the status, navigate to Fine-tuning to view Fine-tuning Jobs.
- Select fine-tuning training job to view its details in the Machine Learning Development Environment cluster.
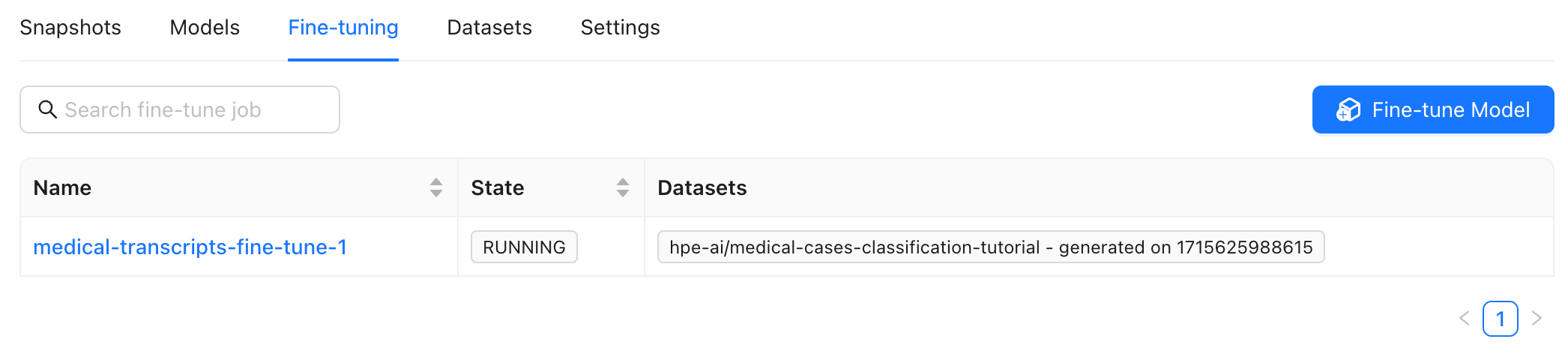
The fine-tuning training job may take a while depending on the size of the job. Once it’s ready, you’ll see the model listed in the Models section of the dashboard.
Recap #
- You’ve initiated a fine-tuning job using a snapshot that combines the model, prompt, and dataset.
- The model is now being refined to better meet your classification needs.