In this tutorial, we’ll build a simple machine learning pipeline in HPE Machine Learning Data Management to train a regression model on housing market data to predict the value of homes in Boston.
Before You Start #
- You must have a HPE Machine Learning Data Management cluster up and running
- You should have some basic familiarity with HPE Machine Learning Data Management pipeline specs – see the Transform and PFS Input sections in particular
Tutorial #
Our Docker image’s user code for this tutorial is built on top of the civisanalytics/datascience-python base image, which includes the necessary dependencies. It uses pandas to import the structured dataset and the scikit-learn library to train the model.
1. Create a Project & Input Repo #
2. Create a Regression Pipeline #
/pfs/out/) created with the same name as the pipeline.3. Upload the Housing Dataset #
4. Download Output Files #
Once the pipeline is completed, we can download the files that were created.
When we inspect the learning curve, we can see that there is a large gap between the training score and the validation score. This typically indicates that our model could benefit from the addition of more data.
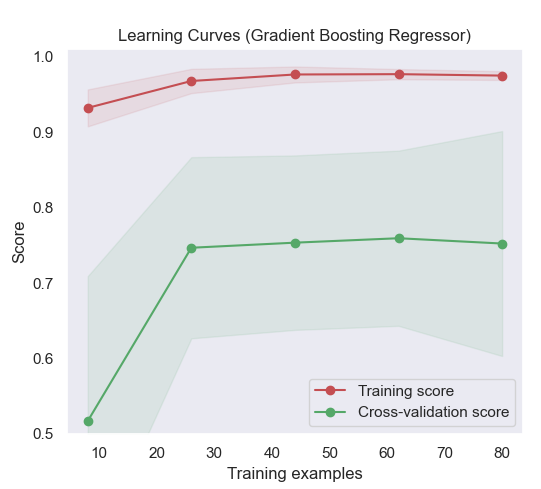
Now let’s update our dataset with additional examples.
5. Update the Dataset #
This is where HPE Machine Learning Data Management truly starts to shine. The new commit of data to the housing_data repository automatically kicks off a job on the regression pipeline without us having to do anything.
When the job is complete we can download the new files and see that our model has improved, given the new learning curve.

6. Inspect the Pipeline Lineage #
Since the pipeline versions all of our input and output data automatically, we can continue to iterate on our data and code while HPE Machine Learning Data Management tracks all of our experiments.
For any given output commit, HPE Machine Learning Data Management can tell us exactly which input commit of data was run. In this tutorial, we have only run 2 experiments so far, but this becomes incredibly valuable as your experiments continue to evolve and scale.
User Code Assets #
The Docker image used in this tutorial was built with the following assets: